David, have you tried tackling this optimisation using a Genetic Algorithm? I can see difficulties: you might need a Connection Machine to do it in a reasonable time, and designing the fitness function is non trivial, but I wonder if it is a suitable problem.
1 Like
With a method like NSGA-II you can use multiple objectives directly rather than trying to cook up a meaningful scalar fitness. Things get a bit tough to visualize after 3 dimensions though.
2 Likes
Thanks. I am sooo out of date on this ![]()
1 Like
Rust impl, worth forking.
Examples of grid compatibility
Comparisons
http://www.ias.ac.in/article/fulltext/sadh/037/06/0675-0694
It is hard to swallow because in the name of security we both set max young to 1 and relocate only on every other churn event. Globally these two elements divide the number of sections by 4 (from 4122 to 1038) and multiply the number of rejections by 3 (from 21000 to 64631).
But I think I understand why: the rejection rate is a security factor for a relatively small network. It can only be reduced if the network grows, which happens naturally because more sections means more available slots for young nodes.
In addition to the rejections (which are accumulated from the start of the network), I will add the instantaneous rejection rate in the displayed metrics. I guess it is the number of sections that cannot accept a young nodes divided by the total number of nodes.
2 Likes
Yes and I agree it feels a bit strict. It is more secure AFAIK and I feel this algo will develop over time where it should become more lenient. Ultimately we do want even very short lived nodes to be of value and earn. Initially though this is possibly safer.
This will be very interesting as well. Thanks again @tfa
3 Likes
The rejection rate has been added in my repo.
I have run a simulation with 890_000 iterations but the result is disappointing: I had hopes that the rejection rate would slowly diminish with the size of the network but that’s not the case and it remains stable with small oscillations around 70%.
| Iteration | Sections | Rejection rate |
|---|---|---|
| 0 | 1 | 0% |
| 10000 | 133 | 73% |
| 20000 | 262 | 70% |
| 30000 | 320 | 66% |
| 40000 | 530 | 73% |
| 50000 | 526 | 74% |
| 60000 | 615 | 68% |
| 70000 | 924 | 68% |
| 80000 | 1052 | 73% |
| 90000 | 1045 | 72% |
| 100000 | 1038 | 71% |
| 110000 | 1033 | 71% |
| 120000 | 1189 | 69% |
| 130000 | 1552 | 67% |
| 140000 | 1768 | 71% |
| 150000 | 2036 | 69% |
| 160000 | 2102 | 73% |
| 170000 | 2098 | 73% |
| 180000 | 2090 | 73% |
| 190000 | 2086 | 72% |
| 200000 | 2079 | 72% |
| 210000 | 2074 | 74% |
| 220000 | 2068 | 72% |
| 230000 | 2084 | 70% |
| 240000 | 2246 | 68% |
| 250000 | 2612 | 68% |
| 260000 | 3018 | 68% |
| 270000 | 3321 | 69% |
| 280000 | 3551 | 70% |
| 290000 | 3707 | 70% |
| 300000 | 3903 | 71% |
| 310000 | 4111 | 70% |
| 320000 | 4191 | 72% |
| 330000 | 4199 | 70% |
| 340000 | 4199 | 72% |
| 350000 | 4194 | 72% |
| 360000 | 4188 | 72% |
| 370000 | 4177 | 73% |
| 380000 | 4171 | 72% |
| 390000 | 4166 | 72% |
| 400000 | 4158 | 71% |
| 410000 | 4150 | 72% |
| 420000 | 4140 | 72% |
| 430000 | 4138 | 71% |
| 440000 | 4135 | 73% |
| 450000 | 4132 | 72% |
| 460000 | 4134 | 72% |
| 470000 | 4182 | 72% |
| 480000 | 4300 | 70% |
| 490000 | 4531 | 69% |
| 500000 | 4851 | 68% |
| 510000 | 5229 | 68% |
| 520000 | 5608 | 68% |
| 530000 | 5979 | 69% |
| 540000 | 6330 | 68% |
| 550000 | 6586 | 70% |
| 560000 | 6870 | 69% |
| 570000 | 7081 | 69% |
| 580000 | 7266 | 69% |
| 590000 | 7451 | 69% |
| 600000 | 7689 | 70% |
| 610000 | 7892 | 70% |
| 620000 | 8111 | 71% |
| 630000 | 8272 | 71% |
| 640000 | 8355 | 71% |
| 650000 | 8395 | 71% |
| 660000 | 8393 | 71% |
| 670000 | 8391 | 72% |
| 680000 | 8393 | 72% |
| 690000 | 8388 | 71% |
| 700000 | 8379 | 72% |
| 710000 | 8368 | 73% |
| 720000 | 8360 | 73% |
| 730000 | 8347 | 72% |
| 740000 | 8341 | 72% |
| 750000 | 8333 | 72% |
| 760000 | 8327 | 71% |
| 770000 | 8318 | 71% |
| 780000 | 8311 | 73% |
| 790000 | 8302 | 73% |
| 800000 | 8299 | 72% |
| 810000 | 8294 | 72% |
| 820000 | 8293 | 72% |
| 830000 | 8286 | 72% |
| 840000 | 8274 | 72% |
| 850000 | 8272 | 71% |
| 860000 | 8272 | 73% |
| 870000 | 8266 | 72% |
| 880000 | 8262 | 72% |
| 890000 | 8258 | 72% |
6 Likes
This is good to know. I really suspect though that we are trying very hard to add nodes, Initially this may be the case, but then I suspect fewer nodes will try and join, However as the network needs more nodes it should get them. This is where the mutation events will help us in ageing nodes faster. So we will need to dive in there a little, the rate of trying to add will diminish over time.
We need to think about that a bit more, as nodes are needed due to the data getting large in a section then we want it to split, so more new nodes / sections will distribute the data better. I think we are missing a tiny bit here. Even with a 70% rejection rate though it is probably not to bad, it is just a few attempts to start (3 or 4) and requesting to join is not all that arduous I suppose.
(still thinking a bit about this one). There are a few of us spending a weekend down at my place this weekend to get space to dive into this a lot deeper, but its a full agenda for the weekend, republish, sgx etc. (GitHub - apache/incubator-teaclave-sgx-sdk: Apache Teaclave (incubating) SGX SDK helps developers to write Intel SGX applications in the Rust programming language, and also known as Rust SGX SDK. - interesting to add security, but limited as well there is also arm trust zone etc.), secure gossip, upgrades and some more. We will spend a while on this as well in a focussed way. I am keen to look a bot more at the assumptions of this sim and the updated one we should publish tomorrow as well, these probabilities of add/rejoin/join etc. I think are close but possibly not as real life as it could be.
[edit, the join rate will also be affected by safecoin, when the network needs nodes it will increase payments and when it does not it will decrease them, so perhaps that also should be factored in somehow, well if it can]
6 Likes
I don’t want to send the Data Chains thread off topic… but just in case you haven’t seen it yet, this recent paper may provide some additional food for thought:
Malware Guard Extension: Using SGX to Conceal Cache Attacks
" Our attack is the first malware running on real SGX hardware, abusing SGX protection features to conceal itself. "
2 Likes
According to the whitepaper, one way to prevent an SGX attack is to use side-channel resistant crypto implementations. Libsodium, fortunately, is implemented, from the beginning, to be extremely resistant to these attacks.
But every day it is more evident that modern CPUs have more holes than a Gruyère cheese.
This factor is, in my view, fundamental. The success of bitcoin comes more from an intelligent application of game theory than from technical implementations.
In the same way, the design of both, the farming rate and the initial distribution, must be adjusted as a reinforcement in security, especially at the beginning when the network is most vulnerable.
From the point of view of an engineer may seem a sin, but, I am convinced that a good advertising campaign and a distribution that incites greed is, for the security of the network, much more important than an ultra-optimized algorithm.
5 Likes
I agree with this principle, but you need to lower the rejection rate to implement it. I also think that a greater number of sections is a better security measure than a greater rejection rate.
To facilitate experiments, I have added a parameter to accelerate or slowdown the relocation rate. Base current formula was: Hash(Event) % 2^(age - init_age + 1) == 0. This parameter modifies it to Hash(Event) % 2^(age - init_age + 1 - relocation_rate) == 0 where relocation_rate = 0 for standard rate and 1 for aggressive rate.
-
Standard rate keeps base behavior with a relocation triggered every other event and with the following probabilities of relocation: 50%: no relocation, 25%: init_age, 12.5%: init_age+1, 6.25%; init_age+2, …
-
Aggressive rate triggers a relocation every event and each probability is shifted one step to the right: 50%: init_age, 25%: init_age+1, 12.5%: init_age+2, 6.25%; init_age+3, …
IMO, there are 2 main models: maximizing or not the number of sections. To have a clear view of the big differences between them, I have launched 2 simulations with 890_000 iterations:
-
the first simulation allows only one young and uses standard relocation rate
-
the second one allows 4 young nodes and uses aggressive relocation rate
Here are the results:
| Metrics | Simulation 1 | Simulation 2 |
|---|---|---|
| Adds | 800814 | 810134 |
| Drops | 62523 | 62976 |
| Rejoins | 26663 | 26890 |
| Relocations | 503815 | 1285360 |
| Rejections | 578686 | 195233 |
| Churns | 1912122 | 3507968 |
| Sections | 8258 | 33405 |
| Section nodes | 161447 | 564058 |
| Left nodes | 26287 | 14370 |
| Rejection rate | 72% | 26% |
4 times more sections will make things harder for an attacker to control a section because he needs much more nodes. This is better than having a greater rejection rate because the attacker has just to retry to connect each node more often but the number of nodes he needs is not impacted.
Another argument is that a greater rejection will deter some casual users from connecting a vault, which will lower the total number of nodes and so will increase the proportion of attacking nodes.
Additional info: section distribution after 890_000 iterations for simulation 1 is:
| Prefix len | Count | Average | Min | Max | Standard dev |
|---|---|---|---|---|---|
| 13 | 8126 | 19.67 | 14 | 26 | 0.84 |
| 14 | 132 | 11.91 | 9 | 20 | 2.10 |
| All | 8258 | 19.55 | 9 | 26 | 1.31 |
for simulation 2:
| Prefix len | Count | Average | Min | Max | Standard dev |
|---|---|---|---|---|---|
| 15 | 32141 | 16.96 | 10 | 37 | 2.31 |
| 16 | 1244 | 14.99 | 9 | 26 | 2.77 |
| 17 | 20 | 13.55 | 11 | 19 | 2.42 |
| All | 33405 | 16.89 | 9 | 37 | 2.36 |
9 Likes
I suppose the downside of sim 2 and the greater number of sections is the much higher churn (ie network overhead)?
There are more churns in simulation 2 simply because the network is bigger, and it is bigger because there are less nodes that cannot connect. So, no downside in this area.
The number of churns is even smaller if we look at the figures when simulation 2 had a similar number of nodes:
| Metrics | Simulation 1 at step 890000 | Simulation 2 at step 260000 |
|---|---|---|
| Adds | 800814 | 234114 |
| Drops | 62523 | 18053 |
| Rejoins | 26663 | 7833 |
| Relocations | 503815 | 376067 |
| Rejections | 578686 | 56978 |
| Churns | 1912122 | 1021403 |
| Sections | 8258 | 8358 |
| Section nodes | 161447 | 163394 |
| Left nodes | 26287 | 3997 |
| Rejection rate | 72% | 27% |
Simulation 2 is much better than simulation 1, except in the number of distinct prefix lengths which varies from 3 to 4: the values are better (I mean prefix lengths are greater) but they are slightly more dispersed than in simulation 1.
So, I improved the program to make sure that when a node is relocated to a section it is placed in the section half having less adults. The simulation is running right now. Results are expected in a few hours.
5 Likes
Result with the new algorithm to balance the sections surpasses all expectations: there is only one prefix length, except during the period of transition from one prefix length to the next one where there are 2.
As a consequence, the number of section is now a stepped curve equaling exactly a power of 2 between each transition (in green):
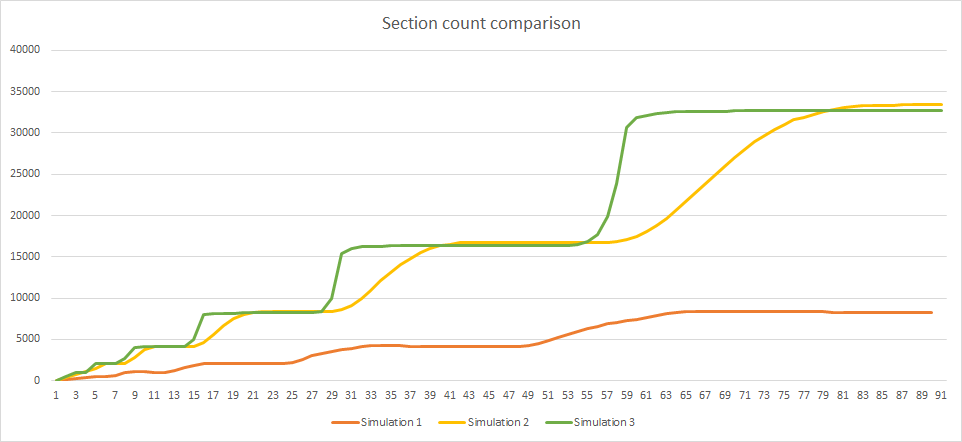
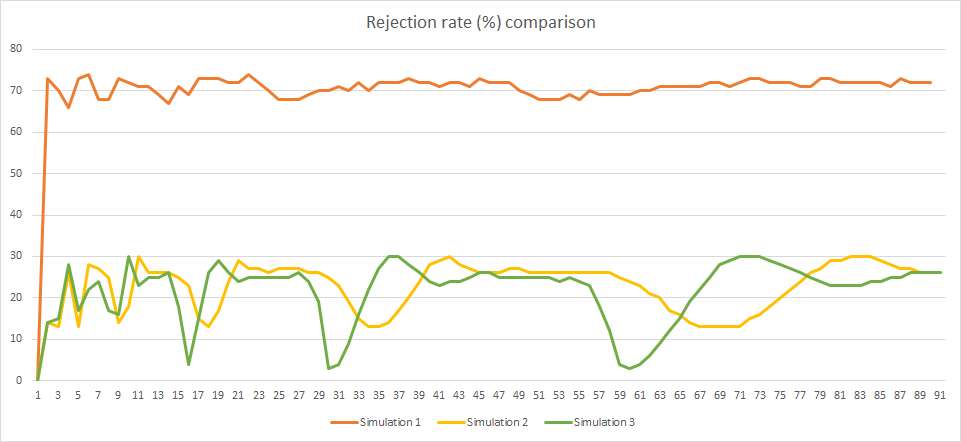
The rejection rate has large oscillations with minimum values at transitions:
The number of nodes is slightly better:
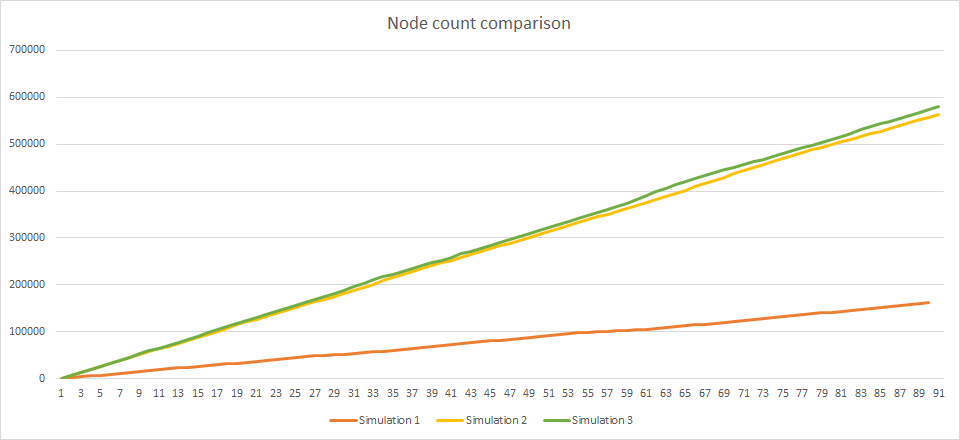
But the real gain of the new algorithm is the homogeneity of the network.
9 Likes
Nice work Thierry, as always.
The question I ask myself is whether it is possible that the network can get more than half a million Vaults in a relatively short time. Which leads me to insist that, beyond the search for technical solutions, socio-economic factors are critical and must be taken into consideration.
What is the expected number of Vaults at the beginning and what growth is expected?
Do we want a Big Bang type of growth or a slower one?
What type of distribution is going to be chosen? Linear, exponential, logarithmic …? And to what extent will this affect the number of Vaults and their growth?
Who and why would someone spend resources attacking the network?
etc etc…
Yesterday a play with the Adam simulation. Those are the result until 12000000 Iterations with standard parameters. Strange behaviour, huge rejections and from 6000000 iterations there are no change in the metrics.
Iterations: 12000000, nodes: 1183, sections: 68, merges: 78, splits: 1217, relocations: 1143 rejections: 510853029 }, AgeDist { min: 4, max: 1079, avg: 258.13 }, SectionSizeDist { min: 9, max: 27, avg: 17.40 }, PrefixLenDist { min: 1, max: 8, avg: 7.12 }, MaxPrefixLenDiff: 7
And this result with relocation-strategy youngest first and 50000000 iterations
iterations: 50000000, nodes: 1606, sections: 94, merges: 104, splits: 1725, relocations: 2710 rejections: 378513740 }, AgeDist { min: 4, max: 1247, avg: 284.62 }, SectionSizeDist { min: 9, max: 32, avg: 17.09 }, PrefixLenDist { min: 1, max: 9, avg: 7.62 }, MaxPrefixLenDiff: 8
4 Likes
I don’t think we can choose the kind of growth because it will depend on farmers willingness to provide vaults and keep them running.
We can help the growth by:
-
Providing incentives for farming (this is what is intended with safecoin rewards)
-
Reducing barriers to farmers wanting to participate (by that I mean minimizing the rejection rate)
But apart these elements, the growth is largely outside our control.
That’s strange. I started with @bart code and I didn’t studied @madadam code nor did I test it. So, I cannot tell where the problem is, but these results are not the expected ones. Maybe the code isn’t ready yet. It could be also a parameterization problem.
That could be the parameter that causes the problem. @bart’s code implements oldest first strategy. It is hard coded, and I left it as it is, because @mav made a convincing case that it is the right choice (youngest first is double discrimination for relocation of old nodes).
2 Likes
5 posts were split to a new topic: Network Health Metrics
This weekend I have added 2 small modifications:
-
I have implemented my idea to replace relocation to the neighbouring weakest section by a 2 steps relocation: first to a distant random section and then to the weakest neighbour of this section. This idea was expressed in this post.
-
Second one is not an improvement but a simplification: I have used the random() function to compute, well … the random section. But in reality vaults cannot use this function because the result will be different between each vault. The randomness must be computed from a common data, typically the hash of an agreed state.
For example, current routing code relocates a joining node to the hash of its name concatenated with the ids of its 2 closest nodes. I don’t think that this algorithm will be kept, but I don’t need to know what the new algorithm will be. The important characteristic for the simulation is that it is a random address, how it will be computed in the real network doesn’t matter.
The same is true for the age of the node to relocate: In @bart code It was computed from the hash of the event, but when we look at @madadam repo, it has been changed to another thing. I make the same argument here: we don’t need to know the final implementation, we only need to compute a random age.
So, I have replaced this usage of hash function by the random function again. Then the hash has been completely removed, because it was not being used anywhere else.
Results are very similar but are slightly less stable (very slightly). I observed two instances with 3 distinct prefix lengths (for example at iteration 310000):
| Prefix len | Count | Average | Min | Max | Standard dev |
|---|---|---|---|---|---|
| 12 | 1 | 17.00 | 17 | 17 | None |
| 13 | 247 | 21.62 | 11 | 25 | 3.35 |
| 14 | 15886 | 12.43 | 8 | 16 | 1.20 |
| All | 16134 | 12.57 | 8 | 25 | 1.69 |
Also, there is sometimes a merge that happens during a stable period with a power of 2 number of sections (for example at iterations 390000, 400000, 410000):
| Prefix len | Count | Average | Min | Max | Standard dev |
|---|---|---|---|---|---|
| 14 | 16384 | 15.38 | 10 | 20 | 1.11 |
| All | 16384 | 15.38 | 10 | 20 | 1.11 |
| Prefix len | Count | Average | Min | Max | Standard dev |
|---|---|---|---|---|---|
| 13 | 1 | 19.00 | 19 | 19 | None |
| 14 | 16382 | 15.77 | 12 | 20 | 1.16 |
| All | 16383 | 15.77 | 12 | 20 | 1.16 |
| Prefix len | Count | Average | Min | Max | Standard dev |
|---|---|---|---|---|---|
| 14 | 16384 | 16.16 | 12 | 21 | 1.18 |
| All | 16384 | 16.16 | 12 | 21 | 1.18 |
Intuitively, I would have thought that relocating nodes at distance is more secure, but these results are not proving this. Though the difference is tenuous: one section over 16000 and I don’t show the curves because they are indistinguishable from previous ones.
Maybe I should add a parameter to allow comparison with more tests. Something like RelocationScope with 2 values (Local and Distant).
9 Likes
I think this mainly applies to attack scenarios like the google attack where particular sections are flooded. This is where the relocation distance matters more.
8 Likes
Exactly. The idea of distant random relocation is not better metrics but avoid possible attacks taking advantage of the relocation in the neighbourhood. An attacker could focus their efforts on a few sections, in whose vicinity has several nodes, and, via DDOS, eliminate certain competitors or even forcing merges. This would allow to be in positions of advantage to gain control of a group.
This type of attack has similarities to games like Go where machine learning via artificial neural network, like AlphaGo, are proving to be extremely effective.
7 Likes